
Text-Driven Video Acceleration: A Weakly-Supervised Reinforcement Learning Method
2023 IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
Abstract
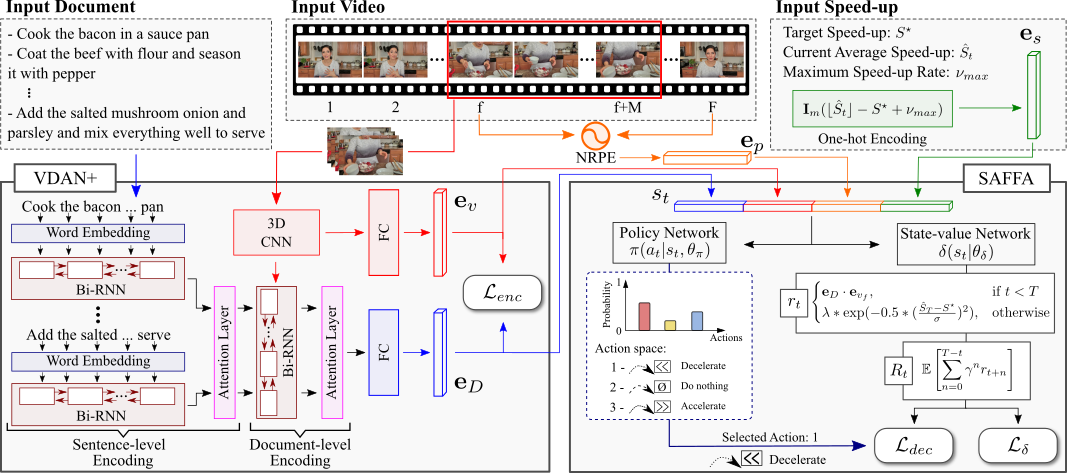
The growth of videos in our digital age and the users’ limited time raise the demand for processing untrimmed videos to produce shorter versions conveying the same information. Despite the remarkable progress that summarization methods have made, most of them can only select a few frames or skims, creating visual gaps and breaking the video context. This paper presents a novel weakly-supervised methodology based on a reinforcement learning formulation to accelerate instructional videos using text. A novel joint reward function guides our agent to select which frames to remove and reduce the input video to a target length without creating gaps in the final video. We also propose the Extended Visually-guided Document Attention Network (VDAN+), which can generate a highly discriminative embedding space to represent both textual and visual data. Our experiments show that our method achieves the best performance in Precision, Recall, and F1 Score against the baselines while effectively controlling the video’s output length.
|
Source code (New!) |
Extra Results |
Citation
@ARTICLE{Ramos2023tpami,
author={Ramos, Washington and Silva, Michel and Araujo, Edson and Moura, Victor and Oliveira, Keller and Marcolino, Leandro Soriano and Nascimento, Erickson R.},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={Text-Driven Video Acceleration: A Weakly-Supervised Reinforcement Learning Method},
year={2023},
volume={45},
number={2},
pages={2492-2504},
doi={10.1109/TPAMI.2022.3157198}
}
author={Ramos, Washington and Silva, Michel and Araujo, Edson and Moura, Victor and Oliveira, Keller and Marcolino, Leandro Soriano and Nascimento, Erickson R.},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={Text-Driven Video Acceleration: A Weakly-Supervised Reinforcement Learning Method},
year={2023},
volume={45},
number={2},
pages={2492-2504},
doi={10.1109/TPAMI.2022.3157198}
}
Baselines
We compare the proposed methodology against the following methods:
- FastForwardNet (FFNet) – Lan et al., FFNet: Video fast-forwarding via reinforcement learning, CVPR 2018.
- Sparse Adaptive Sampling (SAS) – Silva et al., A Weighted Sparse Sampling and Smoothing Frame Transition Approach for Semantic Fast-Forward First-Person Videos, CVPR 2018.
- Sparse Adaptive Sampling (SASv2) – Silva et al., A sparse sampling-based framework for semantic fast-forward of first-person videos, TPAMI 2021.
- Bag-of-Topics (BoT) – Ramos et al., Personalizing fast-forward videos based on visual and textual features from social network, WACV 2020.
Datasets
We conducted the experimental evaluation using the following datasets:
- YouCook2 – Zhou et al., Towards automatic learning of procedures from web instructional videos, AAAI 2018.
- COIN – Tang et al., Comprehensive instructional video analysis: The coin dataset and performance evaluation, TPAMI 2021.
Authors

Washington Luis de Souza Ramos
PhD Candidate
Michel Melo da Silva
Researcher
Edson Roteia Araujo Junior
MSc Student
Victor Hugo Silva Moura
Undergraduate Student
Keller Clayderman Martins de Oliveira
Undergraduate Student
Leandro Soriano Marcolino
Lecturer LU/UK