
Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
Winter Conference on Applications of Computer Vision (WACV)
Abstract
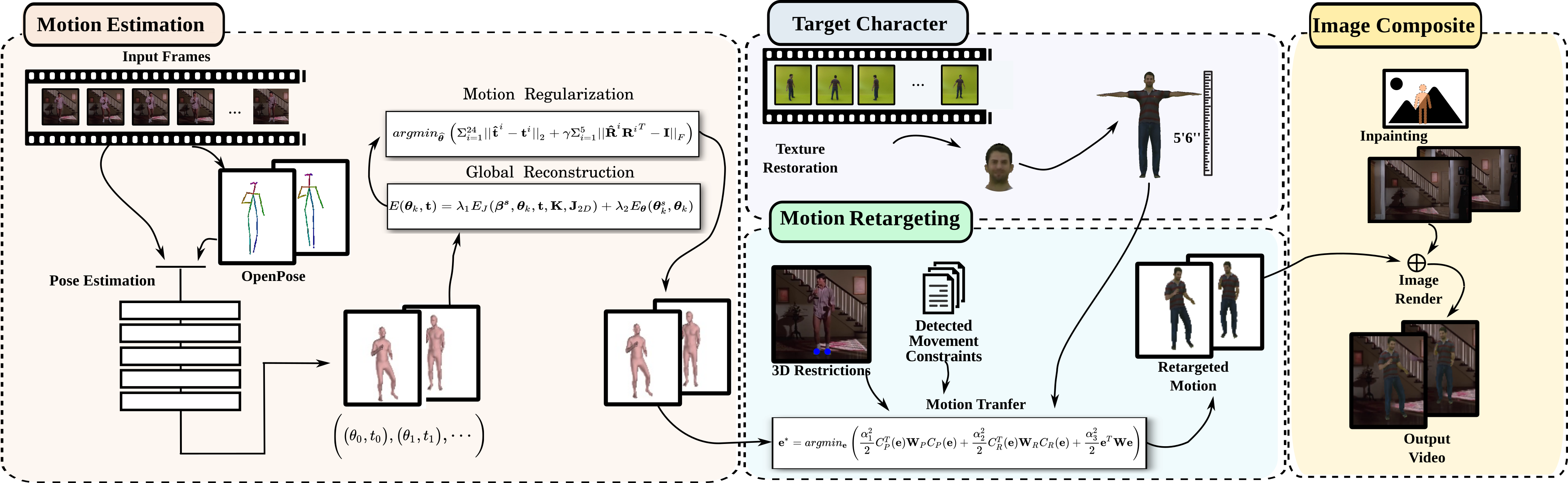
Creating plausible virtual actors from images of real actors remains one of the key challenges in computer vision and computer graphics. Marker-less human motion estimation and shape modeling from images in the wild bring this challenge to the fore. Although the recent advances on view synthesis and image-to-image translation, currently available formulations are limited to transfer solely style and do not take into account the character’s motion and shape, which are by nature intermingled to produce plausible human forms. In this paper, we propose a unifying formulation for transferring appearance and retargeting human motion from monocular videos that regards all these aspects. Our method is composed of four main components and synthesizes new videos of people in a different context where they were initially recorded. Differently from recent appearance transferring methods, our approach takes into account body shape, appearance and motion constraints. The evaluation is performed with several experiments using publicly available real videos containing hard conditions. Our method is able to transfer both human motion and appearance outperforming state-of-the-art methods, while preserving specific features of the motion that must be maintained (e.g., feet touching the floor, hands touching a particular object) and holding the best visual quality and appearance metrics such as Structural Similarity (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS)
|
Source code (Coming soon!) |
Citation
@INPROCEEDINGS {gozes2020wacv,
author = {T. L. Gomes and R. Martins and J. Ferreira and E. R. Nascimento},
booktitle = {2020 IEEE Winter Conference on Applications of Computer Vision (WACV)},
title = {Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints},
year = {2020},
volume = {},
issn = {},
pages = {3355-3364},
keywords = {videos;shape;three-dimensional displays;cameras;motion estimation;skeleton;computational modeling},
doi = {10.1109/WACV45572.2020.9093395},
url = {https://doi.ieeecomputersociety.org/10.1109/WACV45572.2020.9093395},
publisher = {IEEE Computer Society},
address = {Los Alamitos, CA, USA},
month = {mar}
}
author = {T. L. Gomes and R. Martins and J. Ferreira and E. R. Nascimento},
booktitle = {2020 IEEE Winter Conference on Applications of Computer Vision (WACV)},
title = {Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints},
year = {2020},
volume = {},
issn = {},
pages = {3355-3364},
keywords = {videos;shape;three-dimensional displays;cameras;motion estimation;skeleton;computational modeling},
doi = {10.1109/WACV45572.2020.9093395},
url = {https://doi.ieeecomputersociety.org/10.1109/WACV45572.2020.9093395},
publisher = {IEEE Computer Society},
address = {Los Alamitos, CA, USA},
month = {mar}
}
Authors

Thiago Luange Gomes
Researcher
Renato José Martins
Professor at Université de Bourgogne
João Pedro Moreira Ferreira
MSc Student